


Next: Parallelization of VASP.4
Up: The installation of VASP
Previous: Performance of serial code
Contents
The table below shows the scaling of VASP.4 code on the T3D.
The system is l-Fe with a cell containing 64 atoms, Gamma point
only was used, the number of plane waves is 12500, and the number of
included bands is 384.
|
cpu's |
4 |
8 |
16 |
32 |
64 |
128 |
|
NPAR |
2 |
4 |
4 |
8 |
8 |
16 |
|
POTLOK: |
11.72 |
5.96 |
2.98 |
1.64 |
0.84 |
0.44 |
|
SETDIJ: |
4.52 |
2.11 |
1.17 |
0.61 |
0.36 |
0.24 |
|
EDDIAG: |
73.51 |
35.45 |
19.04 |
10.75 |
5.84 |
3.63 |
|
RMM-DIIS: |
206.09 |
102.80 |
52.32 |
28.43 |
13.87 |
6.93 |
|
ORTHCH: |
22.39 |
8.67 |
4.52 |
2.4 |
1.53 |
0.99 |
|
DOS : |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
|
LOOP: |
319.07 |
155.42 |
80.26 |
44.04 |
22.53 |
12.39 |
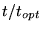 |
|
100  |
99 |
90 |
90 |
80 |
Figure 1:
Scaling for a 256 Al system.
| 3mm
[width=9cm,clip=.true.]origin_new.eps |
The main problem with the current algorithm is the sub space
rotation. Sub space rotation requires the diagonalization of
a relatively small matrix (in this case
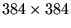 ), and
this step scales badly on a massively parallel
machine. VASP currently uses either scaLAPACK or a fast
Jacobi matrix diagonalisation scheme written by Ian Bush (T3D, T3E only). On 64
nodes, the Jacoby scheme requires around 1 sec to diagonalise the matrix,
but increasing the number of nodes does not improve the timing.
The scaLAPACK requires at least 2 seconds, and scaLAPACK reaches this performance
already with 16 nodes.
), and
this step scales badly on a massively parallel
machine. VASP currently uses either scaLAPACK or a fast
Jacobi matrix diagonalisation scheme written by Ian Bush (T3D, T3E only). On 64
nodes, the Jacoby scheme requires around 1 sec to diagonalise the matrix,
but increasing the number of nodes does not improve the timing.
The scaLAPACK requires at least 2 seconds, and scaLAPACK reaches this performance
already with 16 nodes.
Figure 2:
Scaling of bench.PdO on a PC cluster with Gigabit ethernet..
| 3mm
[width=12cm,clip=.true.]scalePdO_3.2G.eps |
Fig. 2 shows a more representative result on an SGI 2000 for 256 Al
atoms. Up to 32 nodes an efficiency of 0.8 is found.
A similar efficiency can be expected on most current architecture
with large communication band-width (Infiniband, Myrinet, SGI etc.).
On a Gibgabit ethernet based cluster, you can expect an efficiency of 0.75 on 16 nodes,
as demonstrated in the last figure.
Next: Parallelization of VASP.4
Up: The installation of VASP
Previous: Performance of serial code
Contents
Georg Kresse
2009-04-23